
AMD: The Compute Printer.
Q1 2026 ER Digest

This is an update of my original AMD deep dive and Q4 2025 earnings digest.
AMD is my first 100x investment. This is a break down of why I believe it will soon become a 1000X investment and more.
AMD's free cash flow per share is going an order of magnitude or two higher over the next 5-10 years. The platform dominates new AI workloads as they emerge, without reinventing its technology to serve completely different businesses. As scaling laws persist, exponential demand for unforeseen workloads keeps accelerating. We don't know what AI will need next but AMD can deliver a total cost of ownership advantage at scale. This will increase the top line speedily and bring much of that down to the bottom line.
The best proxy for free cash flow per share is earning power, which broadly correlates to the strength and defensibility of the core technology multiplied by the number of vertical applications. AMD mastered chiplets between 2014 and 2021 and built a CPU business on top of that foundation. Free cash flow per share followed fast, because Intel could neither replicate the chiplet platform nor apply it successfully to CPUs. Chiplets won because they delivered higher manufacturing yield upfront and, over time, superior performance at a lower price.
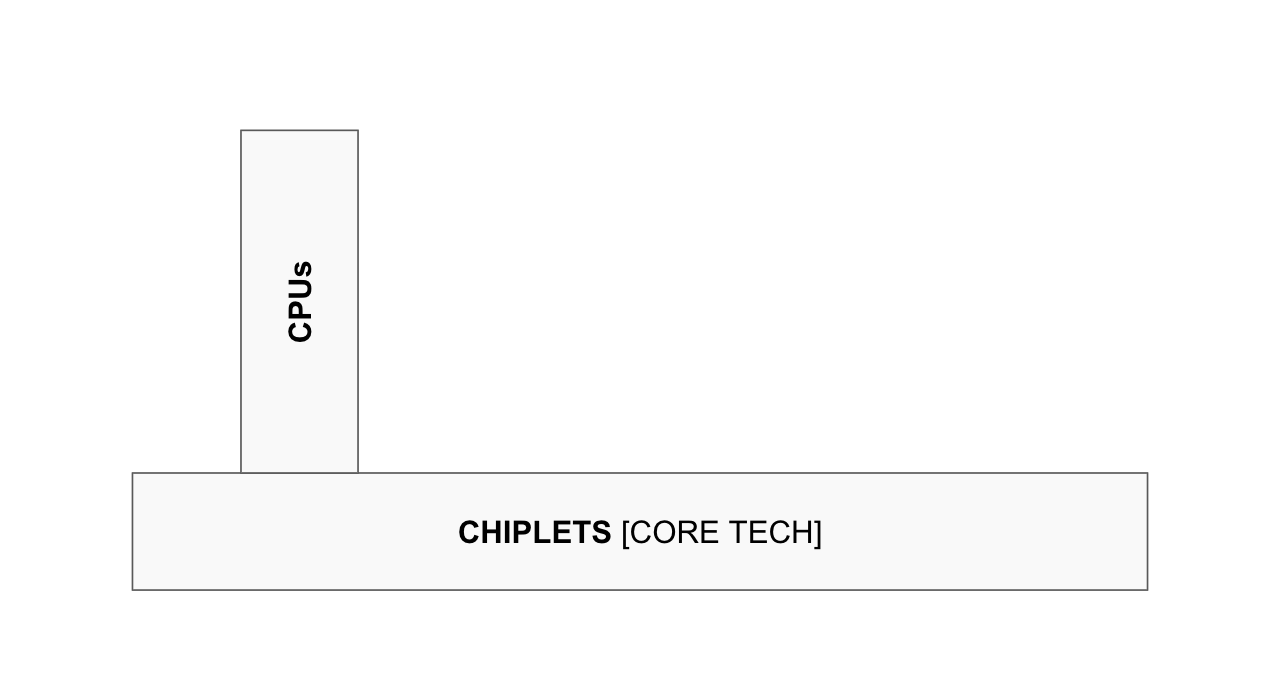
The next chapter has been AMD applying chiplets to grow its AI GPU business, which Zuck and co started leaning into last year. That was one of the strongest signals that the new vertical was gaining traction, and one I highlighted incessantly. But the core thesis always remained that AMD is neither of its verticals. It is a platform with the growing ability to mix and match compute engines at will. A personalised compute printer of sorts, set to become exponentially more valuable as AI generates exponential demand for novel workloads in ways nobody can predict. FPGAs, for instance, are positioned to emerge next as a powerful new vertical instance.
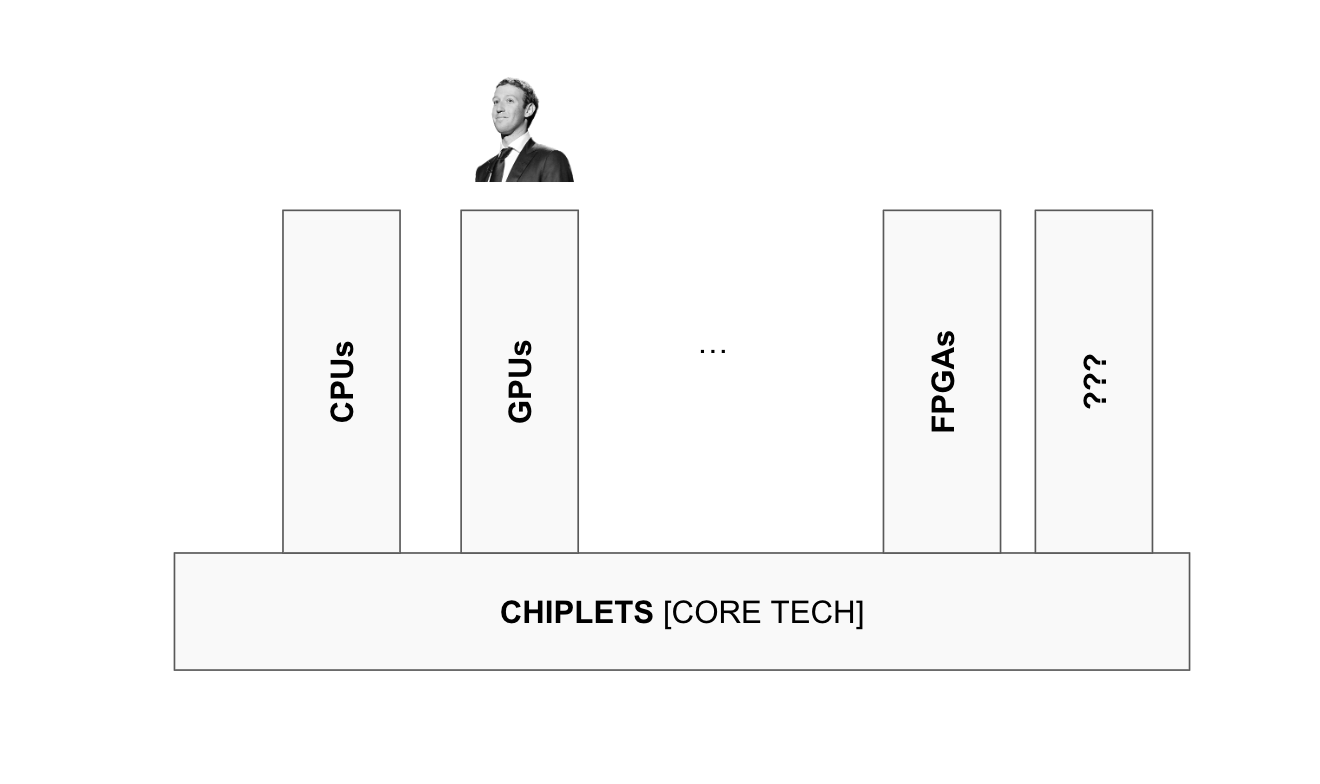
CPUs are hot now because they turned out to be essential for AI workloads. That wasn’t predicted here, but the versatile nature of the platform was. Whatever new AI workload emerges, AMD can be expected to enter the scene with an increasingly dominant position. And most importantly for the long term thesis, we are at the very start of this process. CPU demand today is perhaps the first instance of AI creating demand for a workload nobody foresaw. But as we move towards Agentic AI, Physical AI, and other formats we cannot yet name, the volume of specialised workloads will rise exponentially.
This is where 99% of the upside in the AMD thesis resides.

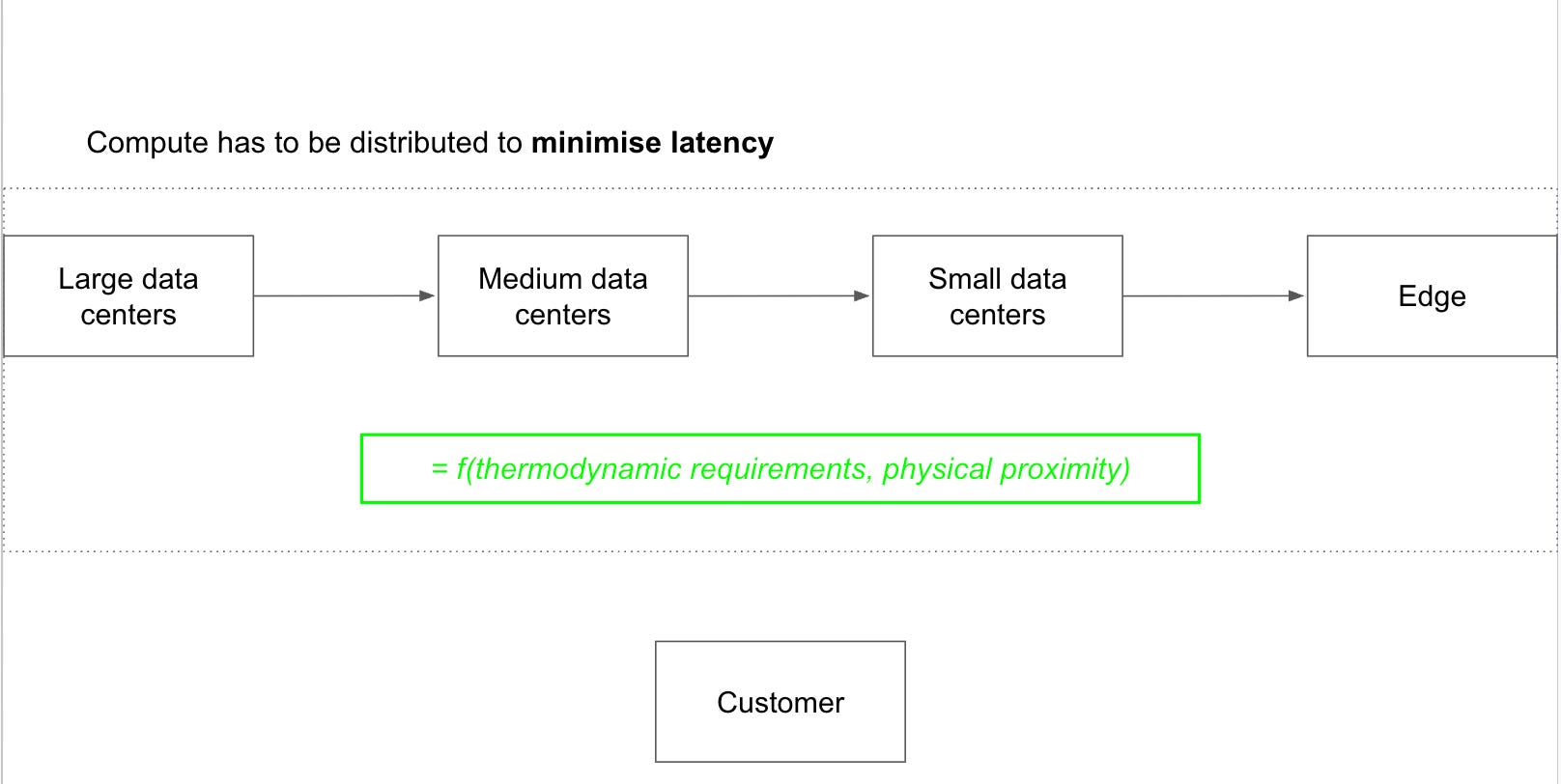
Regardless, customers care about one thing: more intelligence per dollar. This requires optimising the entire compute value chain end to end in order to minimise latency. Some models will require a lot of compute and power to train and will be trained in extremely large datacenters. But the end customer may be far from that large cluster and would experience lower latency pulling inference workloads from a medium datacenter. In that case, it makes sense to train the model in the large datacenter first and then store it in the medium one, where it might be fine tuned over time.
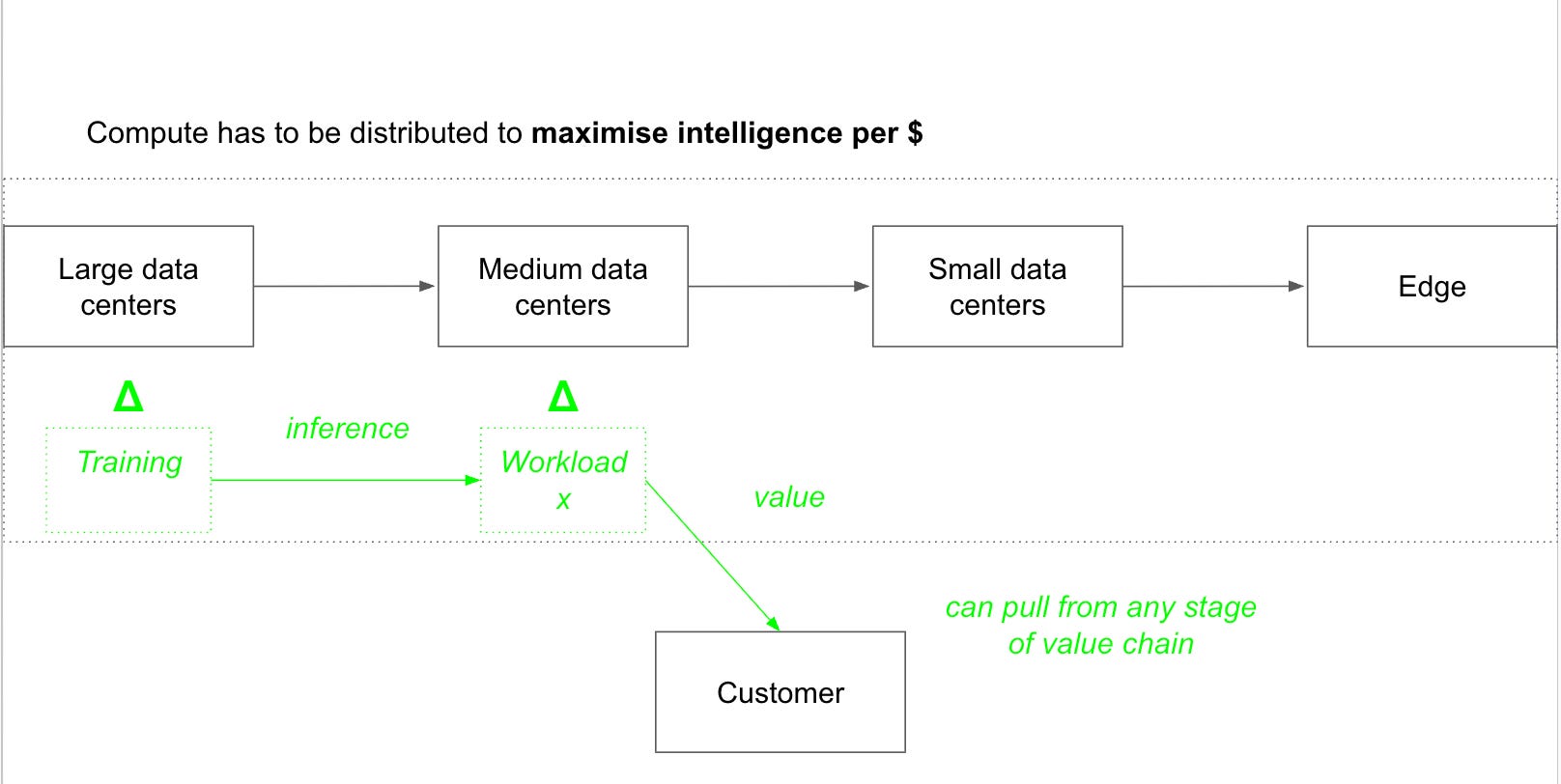
In another example, the customer might be sitting at the Edge using a smartphone. The model in the above example that’s sitting in a medium datacenter might take too long to arrive to his location and therefore, latency would be lower if the model were stored in a small datacenter close to him. This would deliver more value per $ to this customer. Alternatively, the best option might be to store the model locally in his smartphone and have it run inferences locally. That would require a personalised compute engine, capable of storing a large model (lots of memory) and running inferences, on a strict power regimen.
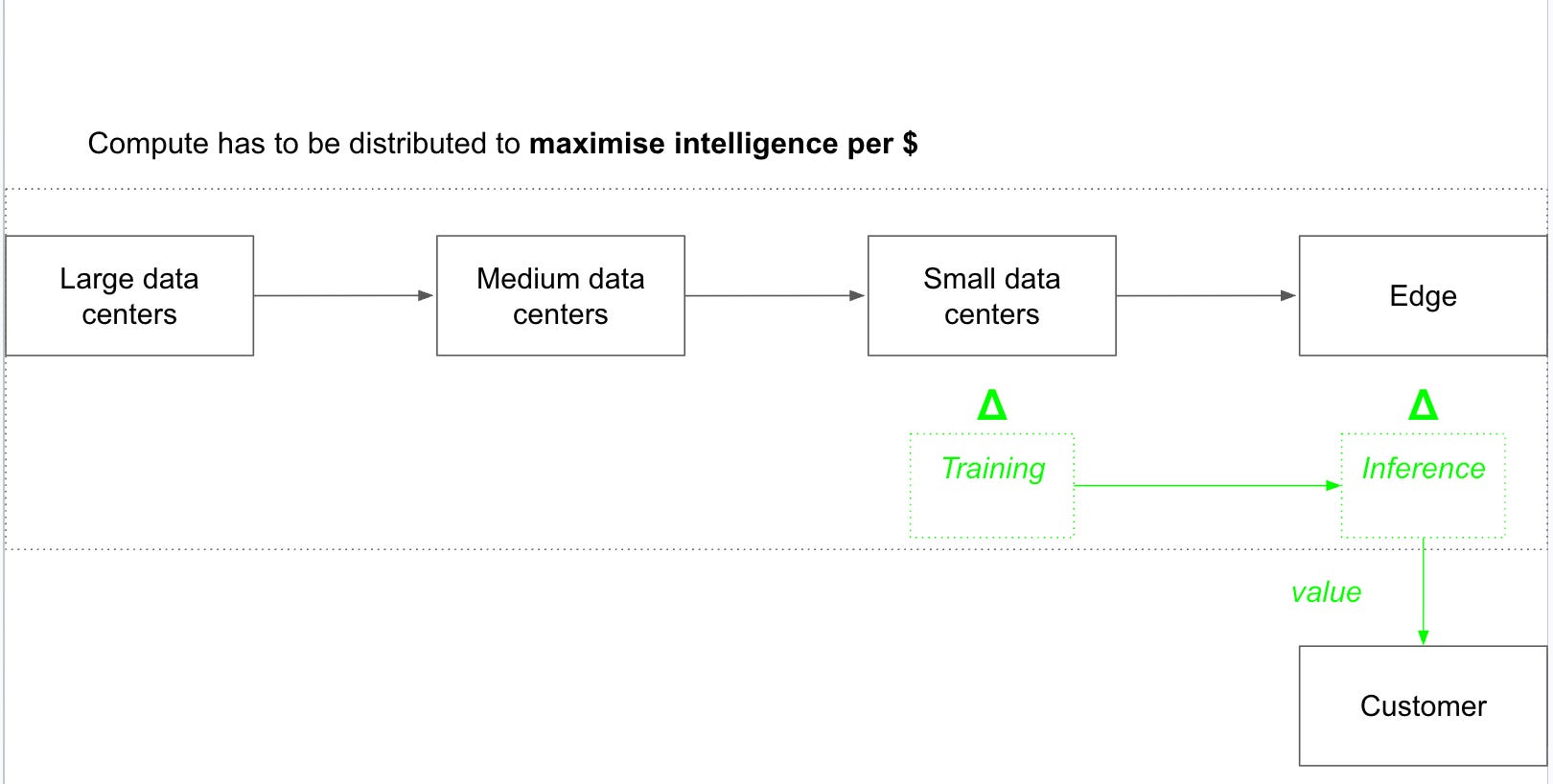
The potential scenarios are endless. This is fundamentally an optimisation problem where the goal is to minimise latency while remaining constrained by thermodynamic requirements and physical proximity. A datacenter in everyone's house would minimise latency perfectly, but it would not be economically viable. A massive datacenter running on everyone's phone would solve the proximity problem, but it would also set the phone on fire. The optimal distribution of compute across the value chain is a function of both constraints simultaneously.
Each case requires a specific solution, and that solution can only be delivered via personalised compute infrastructure at scale.
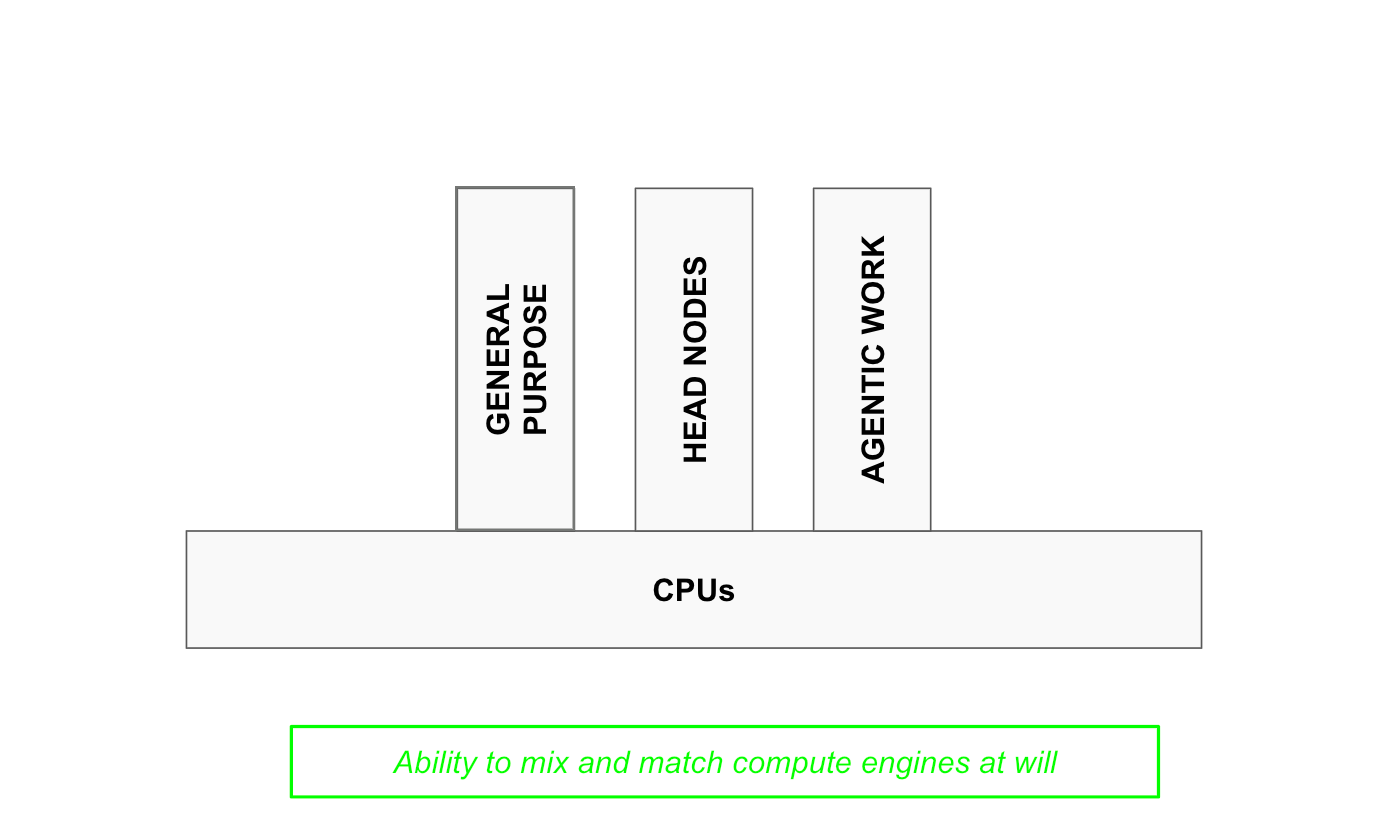
The nature of this problem is fractal. Personalised vertical solutions will tend to verticalize further in pursuit of delivering more value per dollar. CPUs, themselves a vertical instance of the platform, already break down into three further verticals:
general purpose CPUs that can do anything;
head nodes, the CPUs required to prepare data before it enters an AI accelerator;
and agentic CPUs, which power agents after they receive intelligence tokens from AI accelerators.
AMD’s chiplet platform allows them to print any variant or sub-variety of these CPUs at marginal cost. No one can meaningfully compete with that.
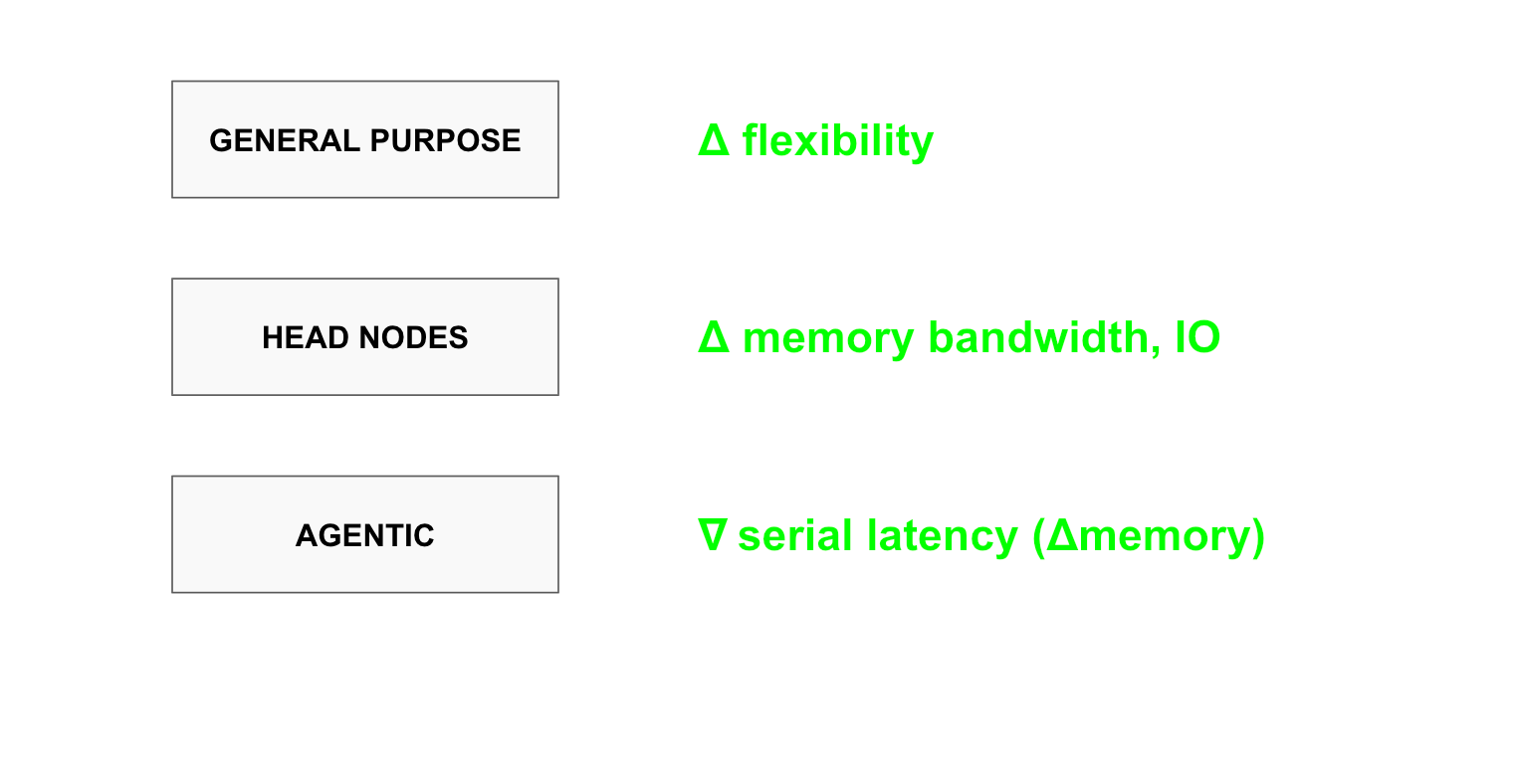
General purpose CPUs need flexibility, because they must be ready to perform any task. Head nodes require higher memory bandwidth and I/O capabilities, since large volumes of data pass through them before reaching AI accelerators. Agentic CPUs need to minimise serial latency while maximising memory, because agents perform one task after another and what they do next depends entirely on what they just did and what is happening in the environment. Each specification demands a specialised architecture, and the average customer will likely need all of them at scale.
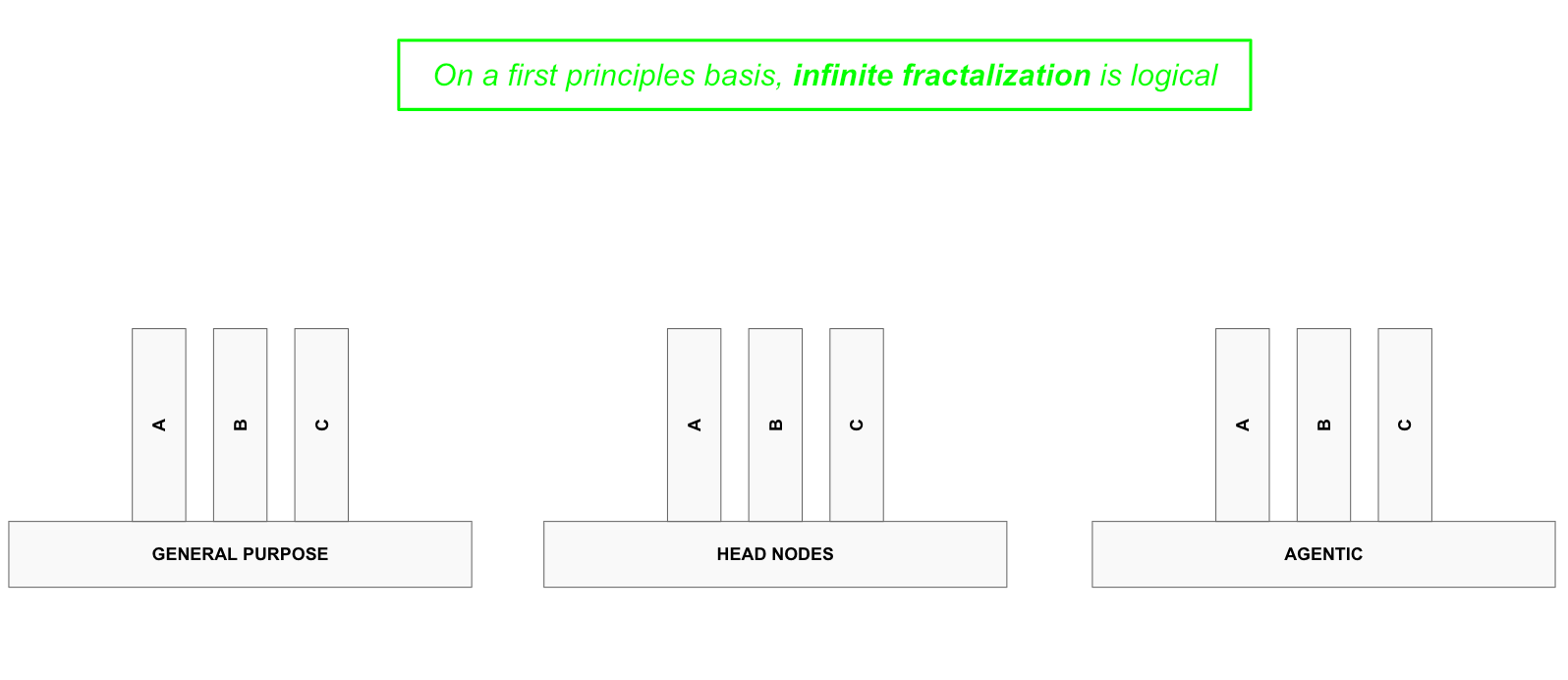
Who is to say we will not see specialised Agent types emerge that require their own architectural configurations to operate profitably? The odds are extremely high for all three CPU types. The verticalisation has no logical end.
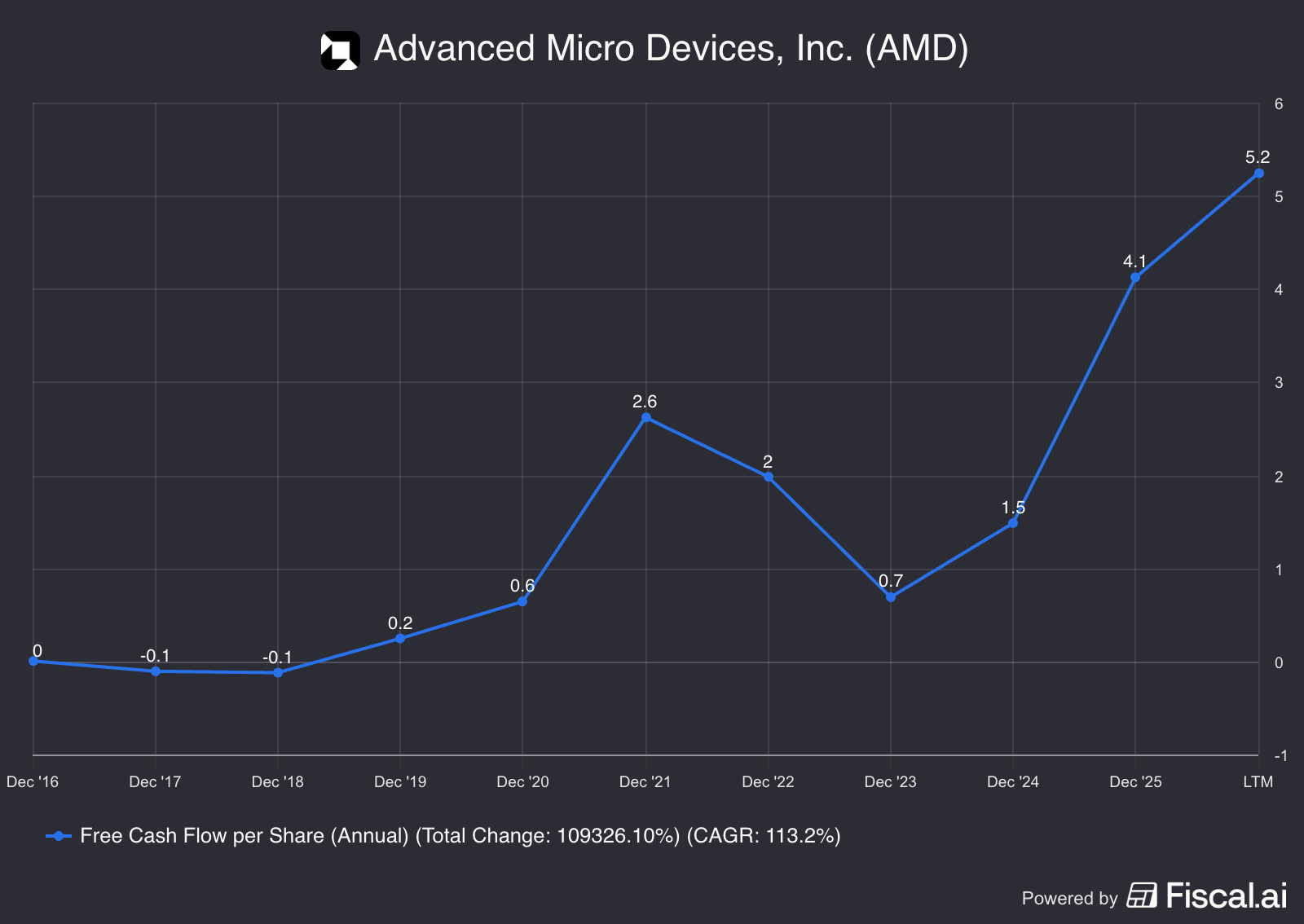
The financials now are appealing because several of these verticals are starting to work in parallel. Over time, the volume and number of these verticals will tend to increase faster as AI scales, with AMD being able to provide at a marginal cost. In this sense, the rise in free cash flow per share below is appealing, but is likely only an appetiser. Over the coming 5-10 years, I believe this metric will rise vertically by several orders of magnitude. This is why I choose to continue holding my AMD shares, despite having obtained a return of 100X since inception.
⚡ If you enjoyed the post, please feel free to share with friends, drop a like and leave me a comment.
You can also reach me at:
Twitter: @alc2022
LinkedIn: antoniolinaresc
As always , amazing insights 🙏Thank you!
Congrats! Keep it going 💯