
Recursion Pharmaceuticals: The Drug Factory That Designs Itself
Deep Dive

This deep dive follows the deployment of the Biology module of my course, in which I teach a first principles framework that enables you to understand biology-based value creation processes.
It sits alongside my other biology deep dives, each one an application of the same lens to a different layer of the stack: Immunity Bio, building a platform to rejuvenate the immune system at marginal cost; Nautilus Biotechnology, building the digital twin of your proteome; and MiNK Therapeutics, turning a forgotten branch of the immune system into an off the shelf cell therapy.
Read together, they map the same thesis across the field: biology is becoming code, and the companies learning to read and write it fastest are the ones that compound.
They claim to have built a superior drug discovery engine. I think they are right. Here is the evidence and why Recursion becomes a Singularity Scaler if the evidence holds.
Every biotech has a pipeline. What Recursion claims to have is something one level up: an engine that produces pipelines, an AI native system that reads biology, designs the molecule, and carries it into the clinic faster and cheaper than the industry, and does so again and again. They call it the Recursion OS, and the framing they want you to hold is that the molecules are merely outputs while the OS itself is the asset.
If that claim is true, then you are not valuing seven early stage programmes at all. You are valuing a learning machine, and learning machines do not grow linearly. Similar to Abcellera, but my impression is Recursion has a far more nuanced understanding of biology.
Which is why the only question that matters is whether the engine is real, rather than whether any single drug works. I believe it is, and the case for it breaks cleanly into four pieces of evidence, followed by what those four pieces add up to once you put them side by side.

1.0 A differentiated Pipeline
A me-too pipeline is really a pipeline of coincidences, where everyone arrives at the same crowded targets because everyone is reading the same literature. Recursion's pipeline does not look quite like that. Management sorts it into three buckets:
The first bucket is novel biological insight, meaning targets the platform surfaced that the field had not prioritised.
The second is emerging biology, validated enough to be interesting but never properly drugged.
The third is validated biology with unmet need, where the target is well known and the job is simply a better molecule.
Most of the Recursion’s seven programmes sit in buckets two and three. CDK7, LSD1, MALT1, MEK in general are all known targets, and that is not where the differentiation lives. The differentiation is the small number of programmes in bucket one, and chiefly one of them, RBM39, which is why that single asset ends up carrying so much of the argument in Section IV.
2.0 They make fewer molecules
To move a single molecule toward the clinic, the industry synthesises somewhere between 2,500 and 5,000 candidates, whereas Recursion synthesises about 330, and it does so in roughly 17 months against an industry average above 40. Ninety per cent fewer compounds at twice the speed is not a rounding error. It is a different cost structure for the same act of discovery.
The mechanism is simple to state: they predict more, so they make less. The biology models and chemistry models simulate which molecules are worth synthesising, so the wet lab only builds the ones the system already believes in. Failure happens in silico, where it is cheap, instead of in glassware, where it is slow and expensive. Recursion truly simulates first and then downloads into physical space.
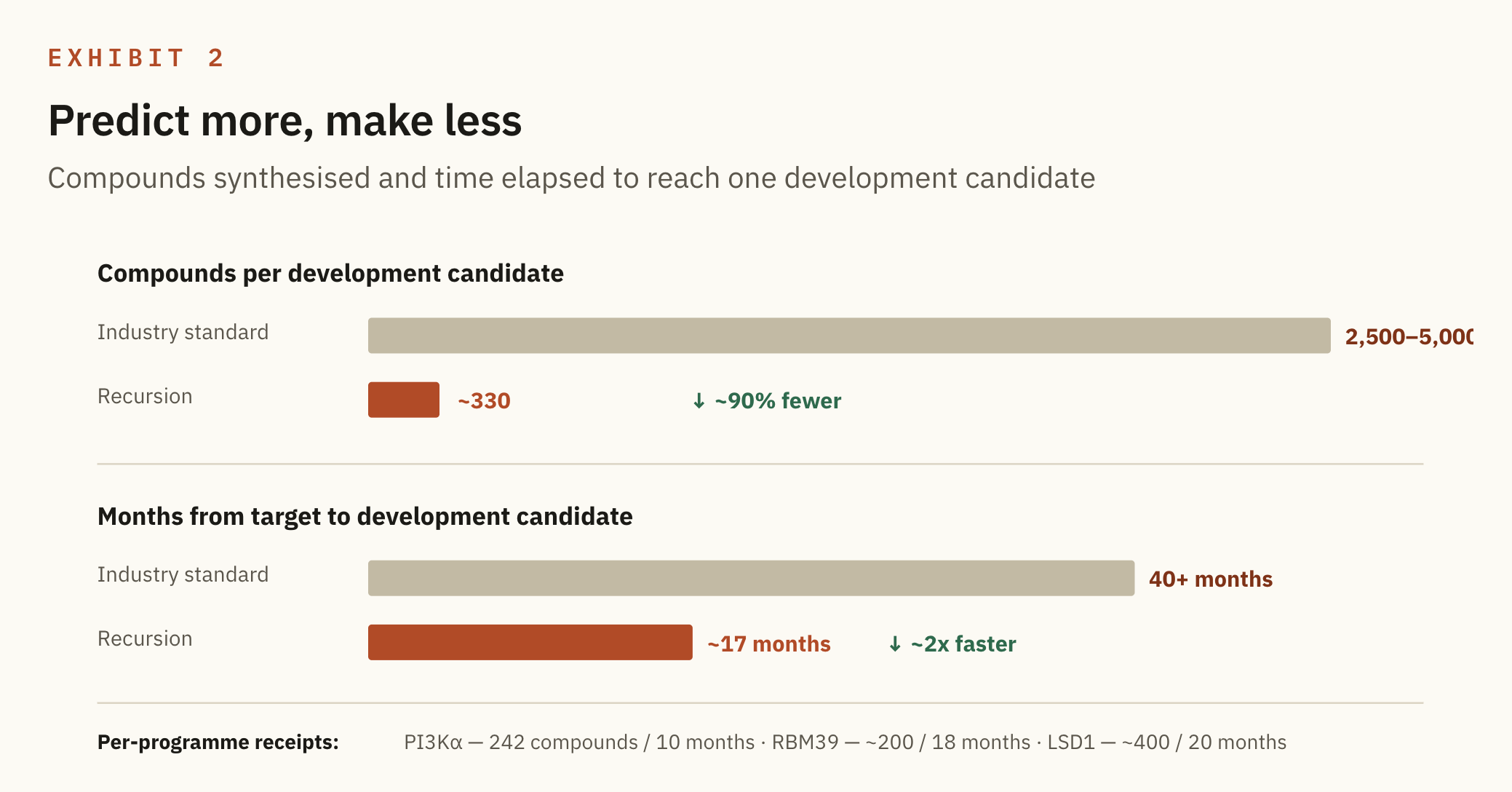
I went looking for movement between the Q3 2025 call and Q1 2026, and the interesting finding is that the headline number barely moved. It sat at roughly 330 compounds and roughly 17 months across all three quarters.
That sounds like nothing, but it is closer to the opposite of nothing. A one off efficiency win is luck, whereas a number that holds steady across quarters, while new programmes are added underneath it, is a process. What changed quarter to quarter was not the average but the pile of per programme receipts sitting beneath it: PI3Kα at 242 compounds in 10 months, RBM39 at around 200 in 18, LSD1 at just over 400 in 20. The stability is the signal, because it tells you they are reporting a repeatable rate rather than a single highlight.
3.0 Some of these drugs do things old methods could not
Two things are happening in this pipeline that conventional discovery struggles to do:
One is reaching a target that has no handle to grab.
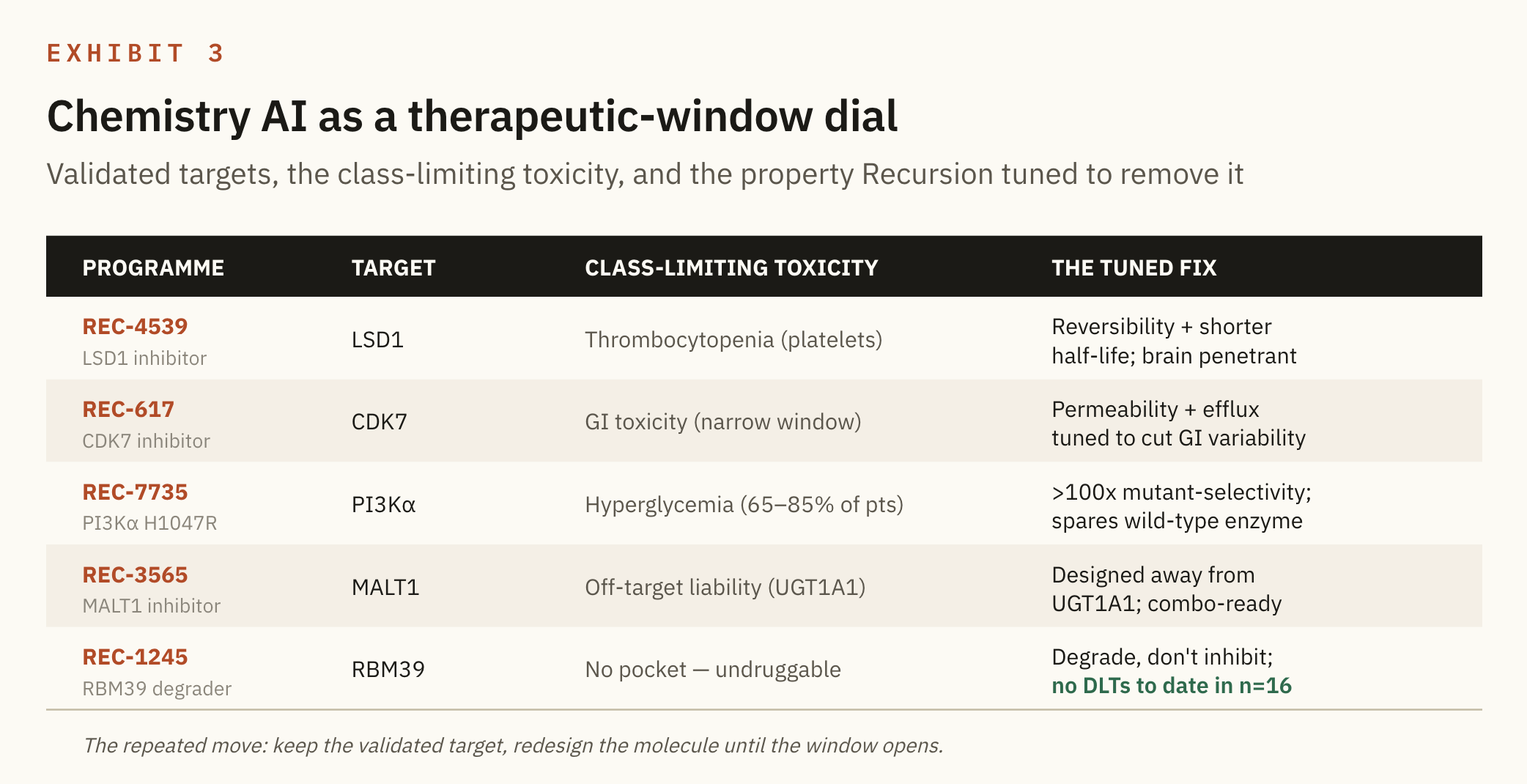
The other, quieter and in my view more underrated, is the chemistry engine tuning a molecule's biological properties just enough to remove the toxicity that killed the entire class before it.
RBM39 is a splicing factor, and in Recursion's own framing it plays a central role in splicing fidelity. It has no convenient pocket to plug, which is why classic inhibitors cannot touch it, so they did not try to inhibit it. They degraded it instead, using a molecular glue that recruits the cell's own disposal machinery and shreds the protein entirely. The point is selectivity by context: tumours already straining their splicing die from the disruption, while cells with margin to spare survive it.

Splicing is the edit step between a gene and the protein it codes for. A freshly transcribed RNA arrives full of stretches that have to be cut out and stretches that have to be kept, and the splicing machinery decides where to cut and what to stitch back together.
That choice is anything but trivial, because by selecting which segments survive, splicing determines which version of a protein a single gene actually produces. RBM39 is one of the proteins that keeps those cuts accurate, so degrading it makes the machinery misfire across thousands of transcripts at once, and the tumours already running their splicing hardest are the ones that cannot survive the errors.
That is the modality story, but the platform story is the better one. RBM39 emerged from genome scale phenomic mapping as a functional analog of CDK12, a relationship the company says was not obvious from sequence homology or pathway analysis. CDK12 is a wanted target that has resisted drugging because it is too similar to CDK13, and hitting both is toxic, yet Recursion's degrader mimics the loss of CDK12 without touching CDK13.
In other words, the engine found a back door into a target the field had been stuck on for years.
Then it translated. The first clinical data came in Q1 2026 across sixteen patients, with, per the company, no dose-limiting toxicities to date and target engagement confirmed. It is early, small, and mid escalation, but the undruggable target is now a tolerated drug in humans, which makes it the single most important fact in the file.
Most of the pipeline is not about finding new targets. It is about rescuing good targets that failed on tolerability. This is where the chemistry AI earns its place, and it is the part the market underweights.
The pattern repeats across the portfolio. A target everyone agrees is valuable has one toxicity that caps the dose below the level where it works, and Recursion uses generative chemistry to redesign the molecule's properties, its half life, its permeability, its selectivity, just enough to widen the therapeutic window. The target stays the same while the molecule changes, and the window itself becomes the product.
4.0 Half a billion dollars says the platform works
Here is the piece of evidence that does not depend on any drug succeeding. Recursion has taken in over $500 million in cash from pharma partners, among them Sanofi, Roche and Genentech, and they are not buying finished medicines. They are buying maps, the proprietary atlases of biology the engine generates.
Consider what that means. The most sophisticated R&D buyers in the world, companies that could in principle build this themselves, are writing cheques for the engine's raw output. Roche paid a milestone for a whole genome map of microglia, the immune cell of the brain, something many people did not believe could be built at all, and Sanofi has accepted five lead packages on hard targets.
This is the clearest validation in the file precisely because it is market priced. It does not prove any Recursion drug will be approved, but it does prove the underlying platform produces something valuable enough that pharma pays cash for it today. And that correlates directly with the differentiated nature of the molecules, because the same maps Roche buys are the maps that surface targets like RBM39.
If pharma pays for the maps, the maps are real. If the maps are real, the molecules built on them are not coincidences.
5.0 A closed loop on physics, chemistry and biology
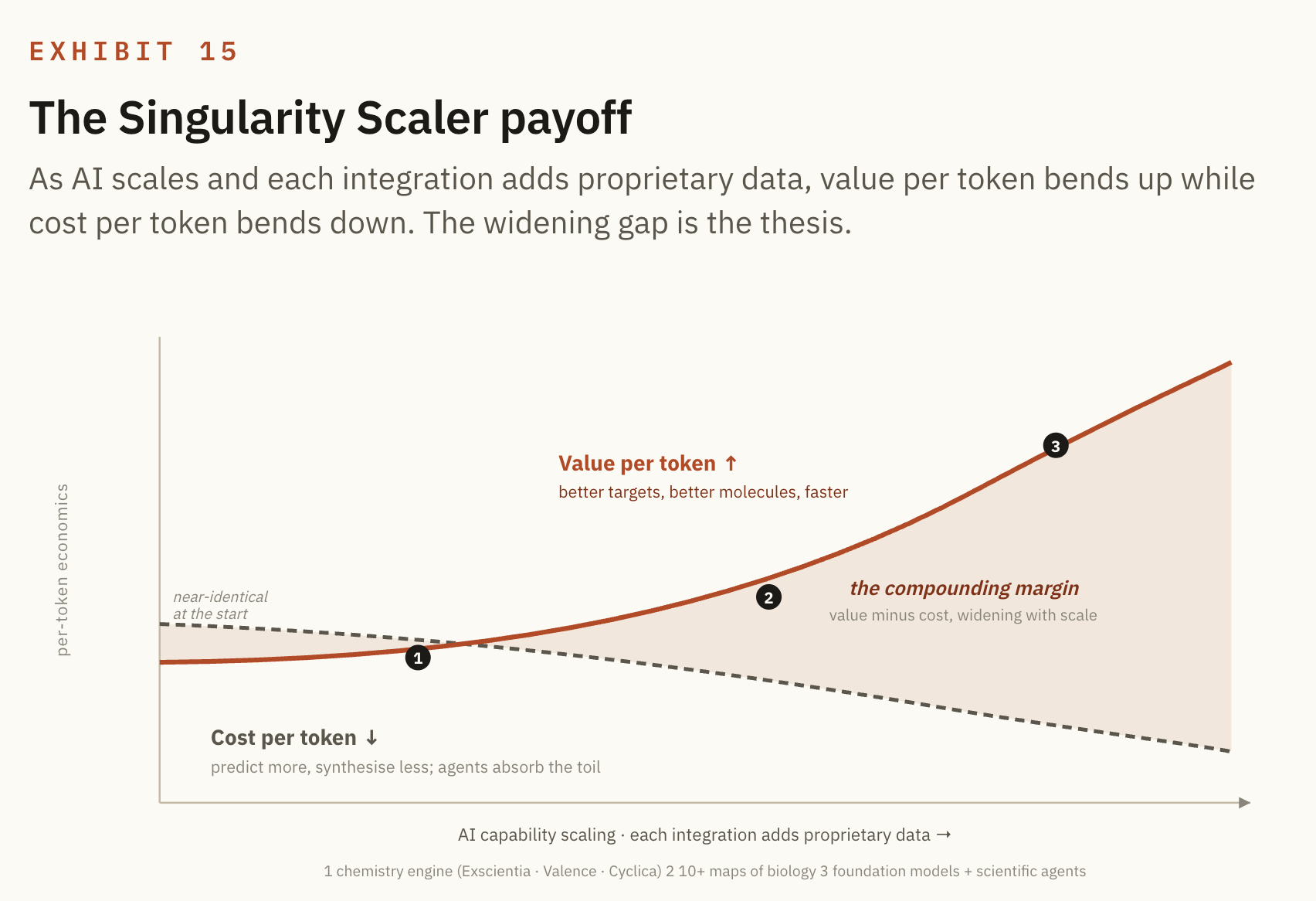
And this is where the framework I have been building for years applies directly. A business whose output decouples from its input, and that grows exponentially more powerful at near zero marginal cost as AI compounds, is what I call a Singularity Scaler. Recursion has the shape of one, because every map they sell funds the next map, and every experiment, success or failure, feeds back as proprietary data that makes the next model better.
The engine pays for its own improvement.
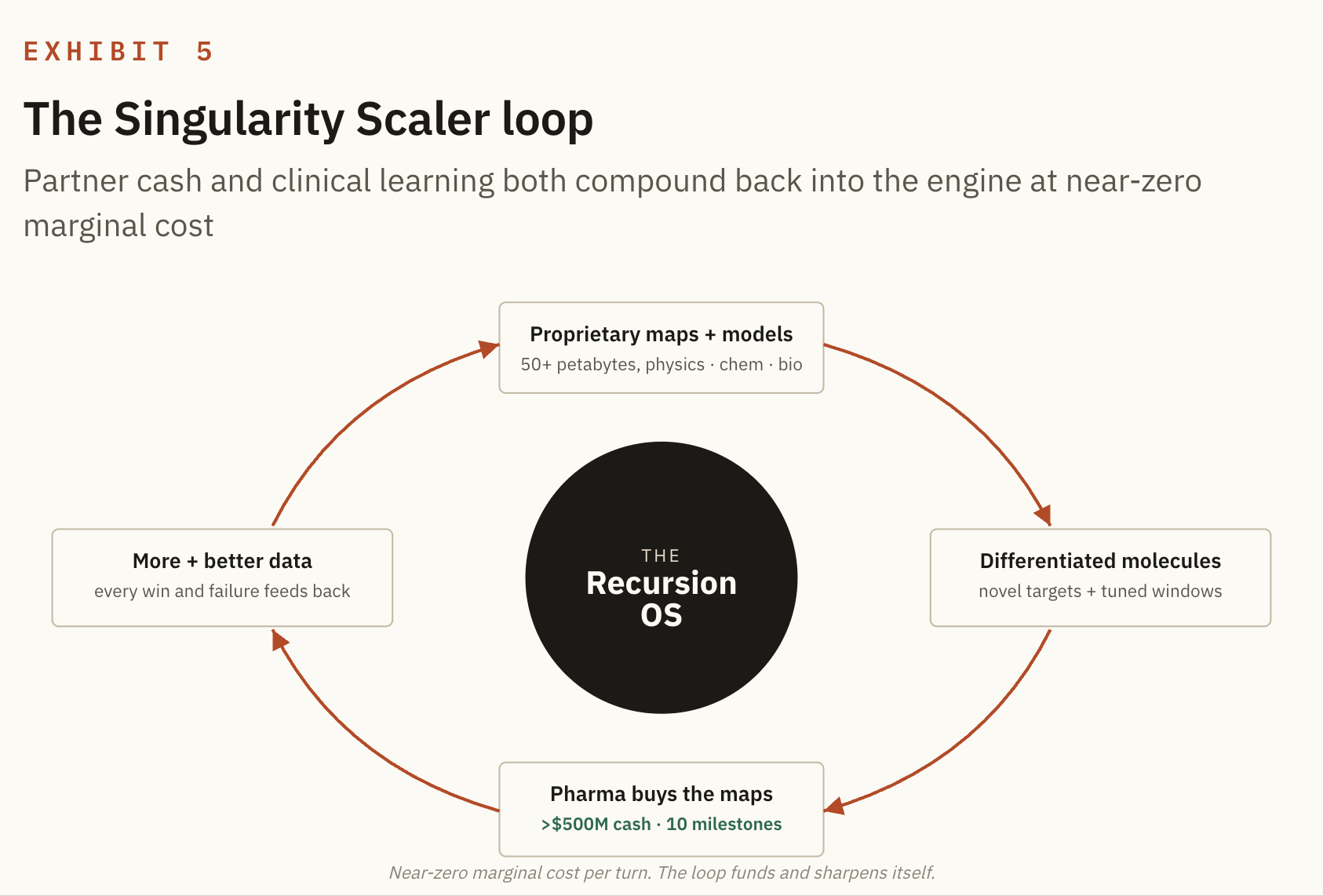
A closed loop that learns the rules of biology and turns them into better medicine per dollar. The wet lab generates data, the dry lab builds models, the models predict, the lab tests the predictions, and the results, right or wrong, retrain the models. Round and round, getting tighter with each turn.
The reason this matters more than any single model is that drug discovery is a chain of decisions rather than one decision, so improving a single step is not enough. The value comes from compounding better decisions across the whole chain, from target to molecule to patient, and that is the thing an end to end loop does that a point solution cannot.
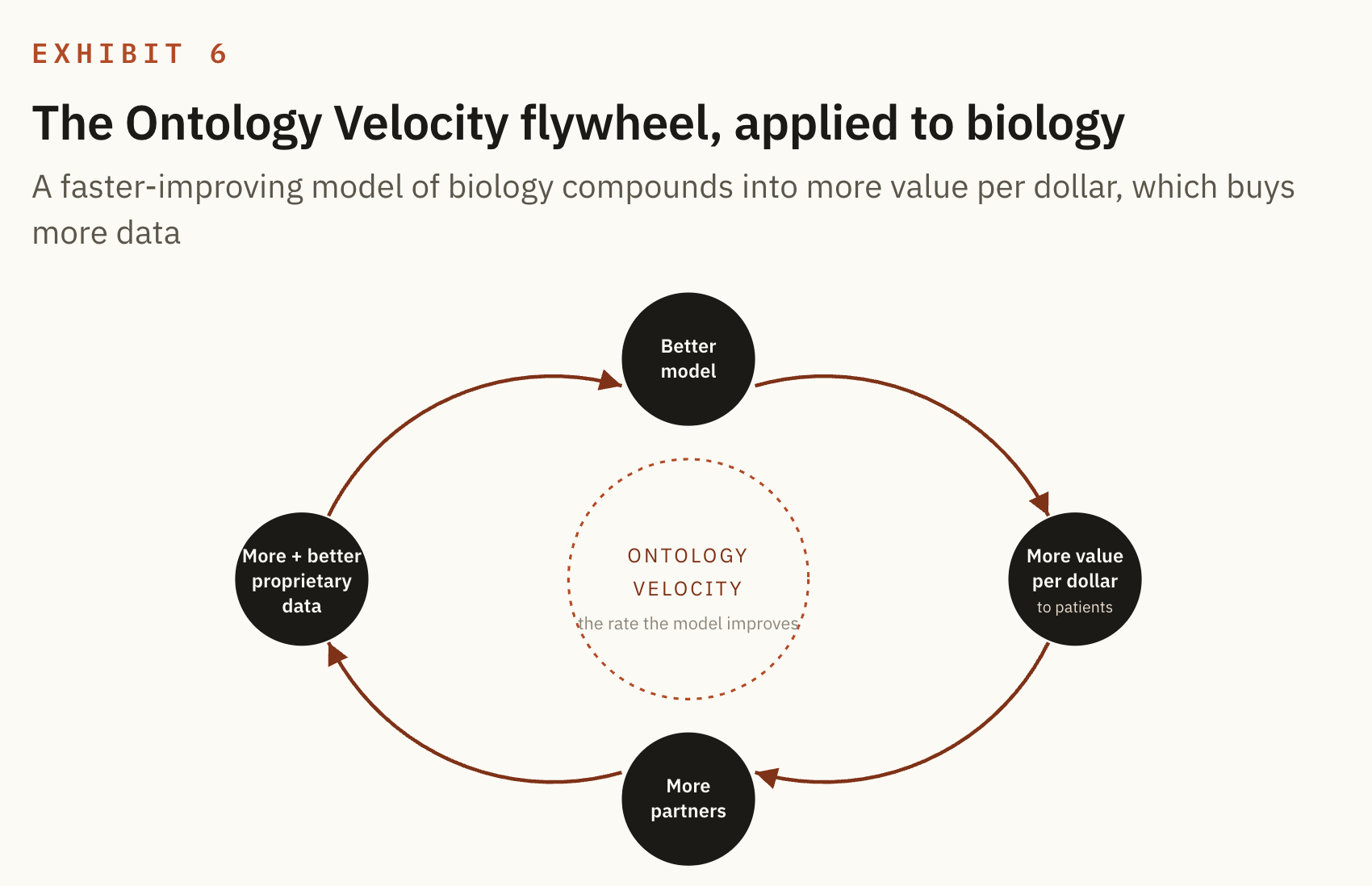
This is precisely the thing I named Ontology Velocity. Every company has an ontology, a working model of the world it operates in, built from the data it collects. The faster that model improves, the faster the company delivers more value per dollar. In an AI native world, the company with the fastest improving ontology does not just win. It opens a gap that compounds until it becomes uncrossable.
Recursion's ontology is biology itself. Their loop is a machine for improving that ontology faster than anyone else can. That is the whole bet, drawn as a flywheel.
Operationally, the loop is now spawning its own workforce. Recursion is building internal scientific agents: AI systems that sit inside the process, read the data, propose hypotheses, choose experiments, and capture the reasoning trail so the next agent is smarter. They do not replace the scientists. They remove the toil so the scientists do more of the hard part.
This is the economies of scale answer for a TechBio company. You do not scale by hiring linearly, you scale by letting the agents absorb the repetitive cognition, and that is what bends the cost curve down while the output curve bends up. It is the Singularity Scaler mechanism again, this time expressed in headcount.
6.0 A printer for medicine
Follow the loop forward and you arrive somewhere strange. Today the engine designs molecules one programme at a time, but the thing actually being built is not a molecule designer. It is a model of biology.
If the ontology keeps improving, the unit of output stops being a drug and starts being a capability. Give the system a target, a patient and a context, and it designs the molecule, first for a class of patients, then eventually for the patient sitting in front of you. A system that does not search for medicine so much as compute it.
That endpoint is years away and may never fully arrive, since biology is nowhere near finished being mapped, and the company will be the first to tell you only about ten per cent of it is understood. But the direction is the point, because a model that designs and prints personalised medicine on demand is, by construction, almost impossible to displace. You would not be competing with a drug, you would be competing with an accumulated understanding of biology that took a decade and fifty petabytes to kickstart.
7.0 Seven molecules, on first principles
Biology is code and the primary question is how deep into that code you have to reach. The shallowest intervention works at the signalling layer, the dynamic messages a cell is sending right now. Reach deeper and you arrive at the epigenome, the instructions that decide which genes get read at all. Deeper still sits the genome itself, the source code. And when none of that can be repaired in place, the last resort is to replace the hardware altogether with cell therapy.
That is my ladder for the whole field: peptides, then the epigenome, then the genome, and cell therapy if all of that fails. Signal, then reading, then source, then replacement. The deeper the rung you are forced to touch, the harder the delivery becomes and the more radical the intervention, which is why a company would always rather solve a disease high on the ladder than low on it.
Here is where Recursion's seven molecules actually sit.
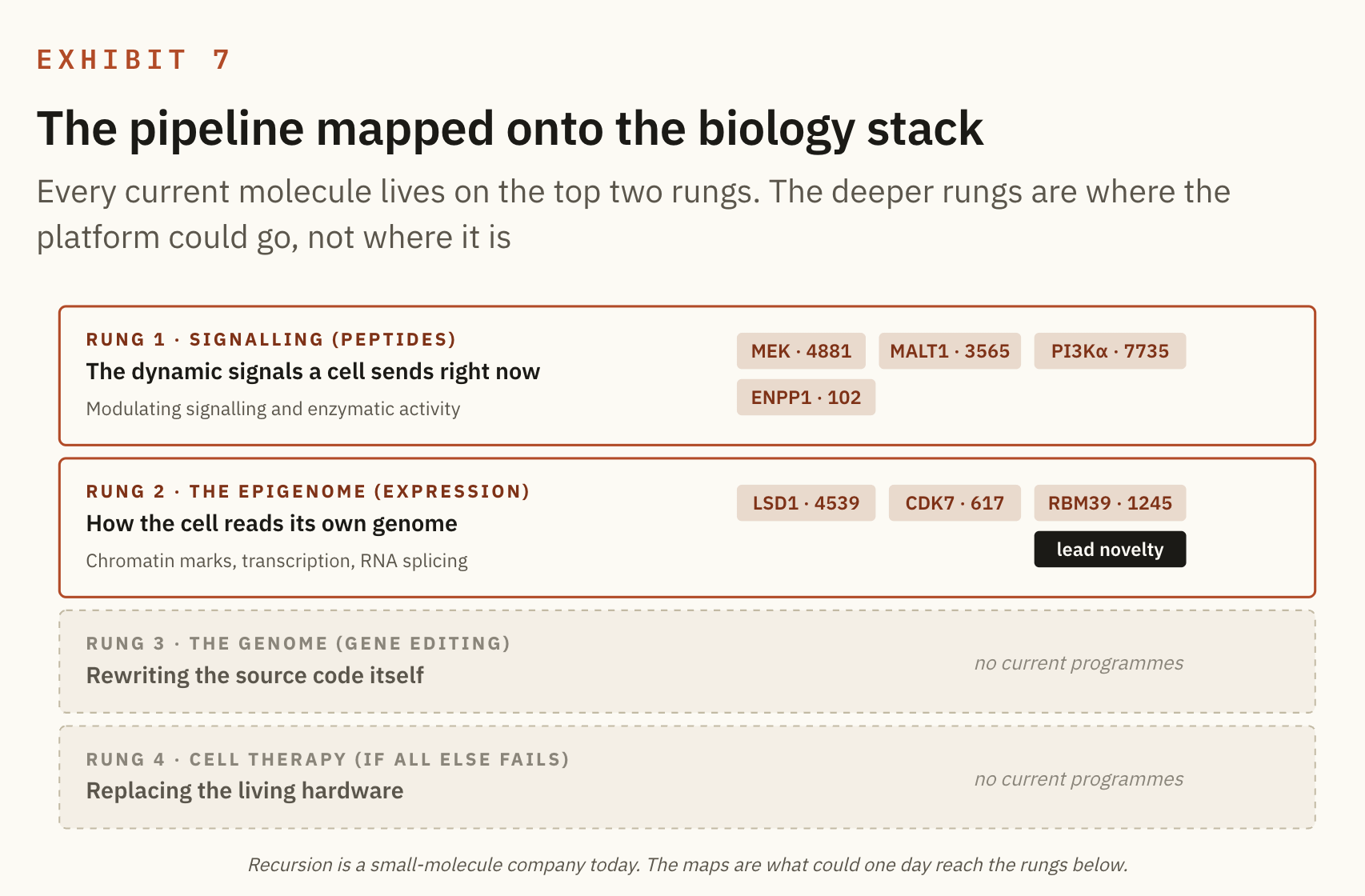
The map says something the company never quite states outright. Every molecule it is running today sits on the top two rungs, which makes it a small molecule house operating at the signalling and epigenome layers. It does not edit genes and it does not build cells, and that is not a criticism so much as the actual shape of the thing, because the deeper rungs are where the maps could one day lead rather than where the drugs are now. With the ladder in place, here is each molecule on first principles, and how each one actually works.
The signalling layer
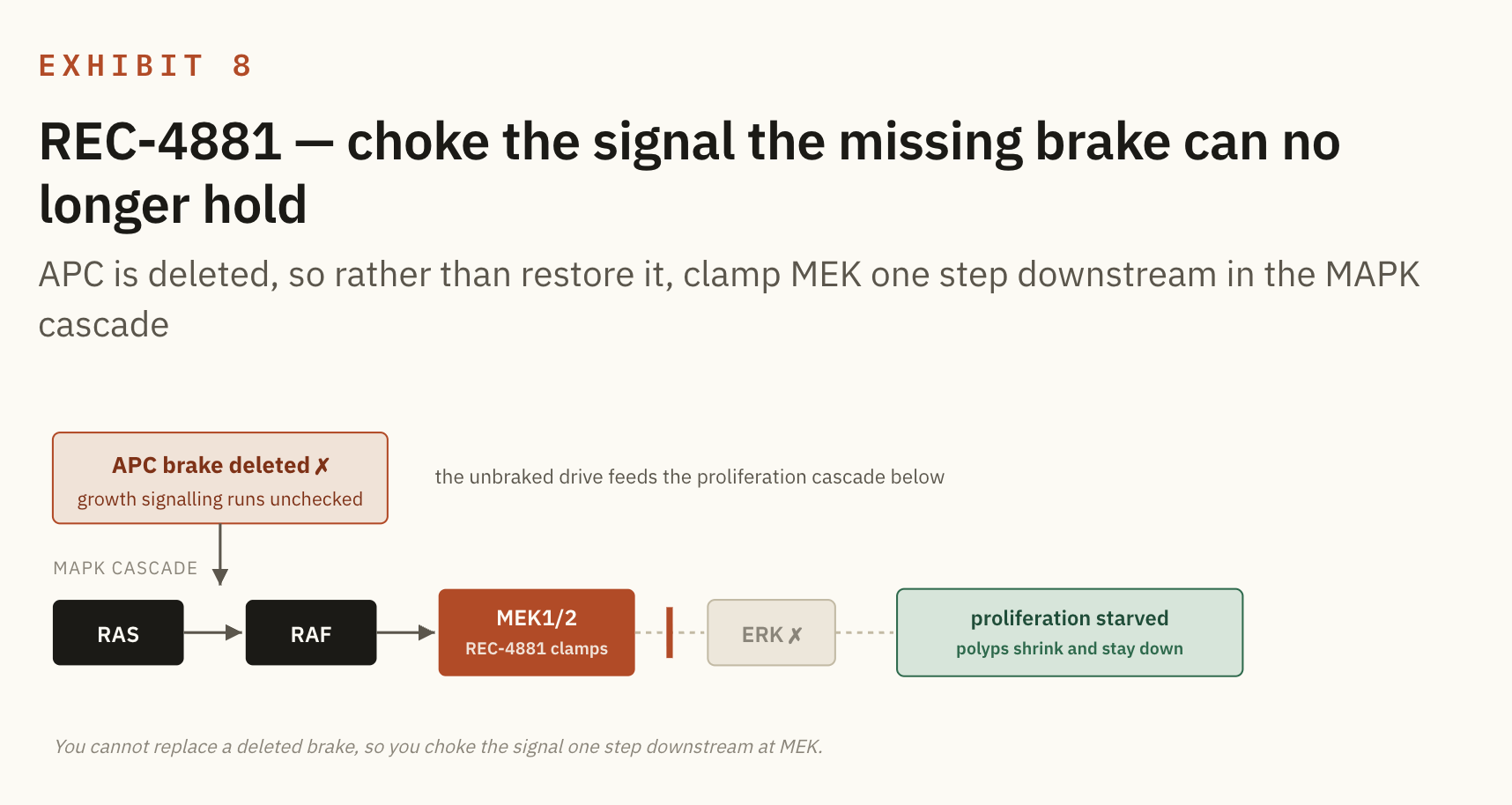
REC-4881 (MEK1/2, FAP). FAP patients inherit a broken APC gene, the brake on Wnt signalling, and without the brake the colon carpets itself in precancerous polyps. You cannot easily restore a deleted gene, so REC-4881 clamps a node downstream, MEK, the dedicated gateway to ERK, and starves the polyps of the growth signal they lean on.
The edge over standard of care is notable, because there is no standard of care: surgery is the option. The Phase 2 showed a 43% median polyp reduction with durability off treatment, and the platform edge is that phenomics surfaced, without a prior hypothesis, that MEK inhibition would attenuate the disease at all.
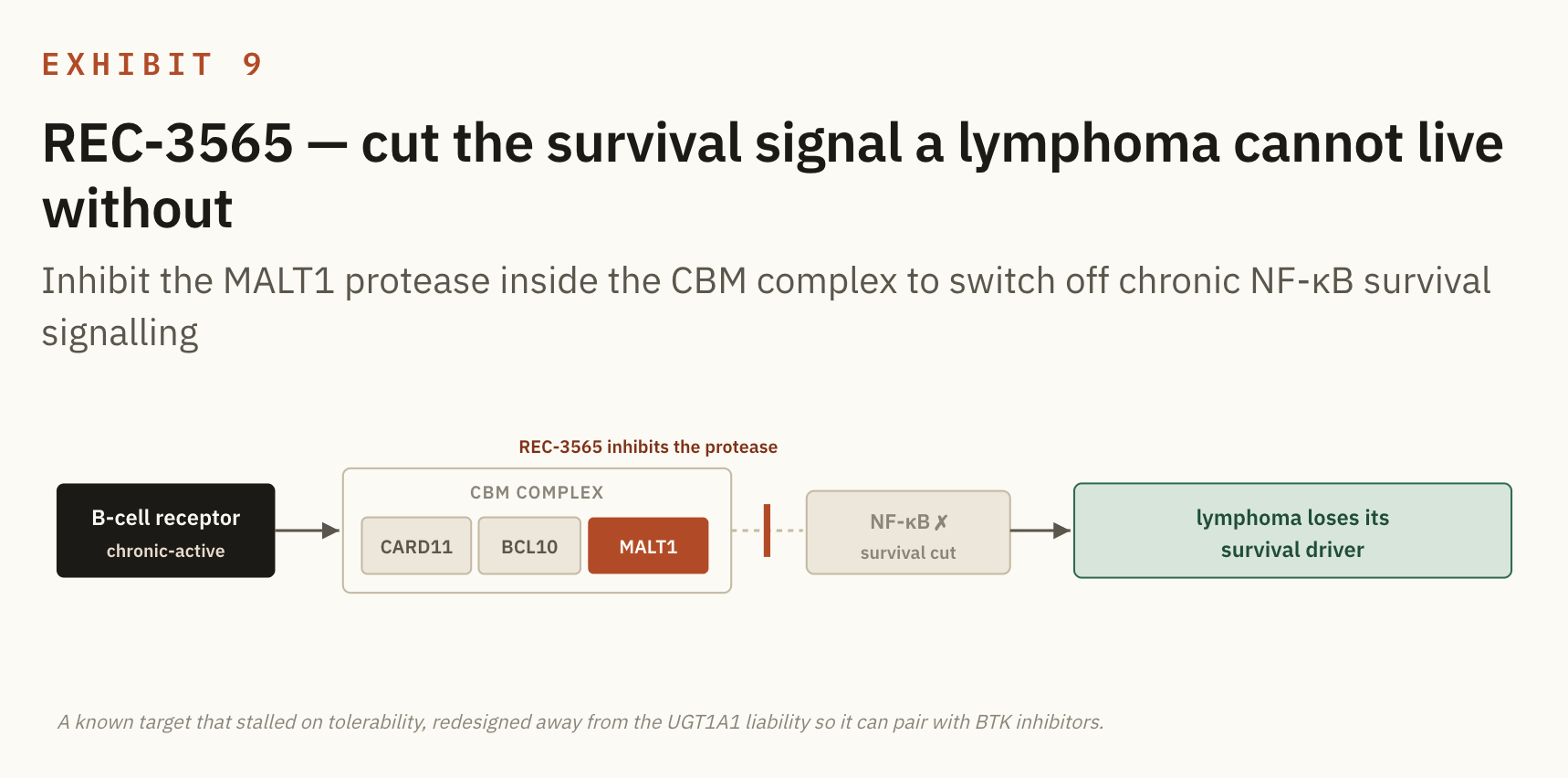
REC-3565 (MALT1, B-cell malignancies). MALT1 sits in the survival signal that B-cell lymphomas run on, so it is a known and validated target, and the reason it stalled was tolerability rather than biology. The platform edge here is pure chemistry: a molecule designed away from the UGT1A1 liability, so that it can be combined with BTK inhibitors, which is where the real value in this setting sits.
REC-7735 (PI3Kα H1047R, solid tumours). PI3Kα is one of the most important oncogenic targets there is, yet existing drugs cause hyperglycemia in 65 to 85% of patients because they hit the healthy wild type enzyme as well as the mutant. Recursion used molecular dynamics to find a novel pocket and designed a molecule with over 100x selectivity for the mutant form, so the edge is the same powerful target without the metabolic toxicity that limits how long patients can stay on it.

REC-102 (ENPP1, hypophosphatasia). This is the odd one out, and an insightful first principles move. Patients cannot clear pyrophosphate, which is the molecule that blocks bone mineralisation. This means their bones get weaker over time.
Since you cannot easily fix the broken clearing enzyme, Recursion instead inhibits ENPP1, the enzyme that produces the pyrophosphate in the first place. It cuts the supply rather than trying to restore the disposal, and the edge is convenience: an oral molecule against today's burdensome injected enzyme replacement.

The expression layer
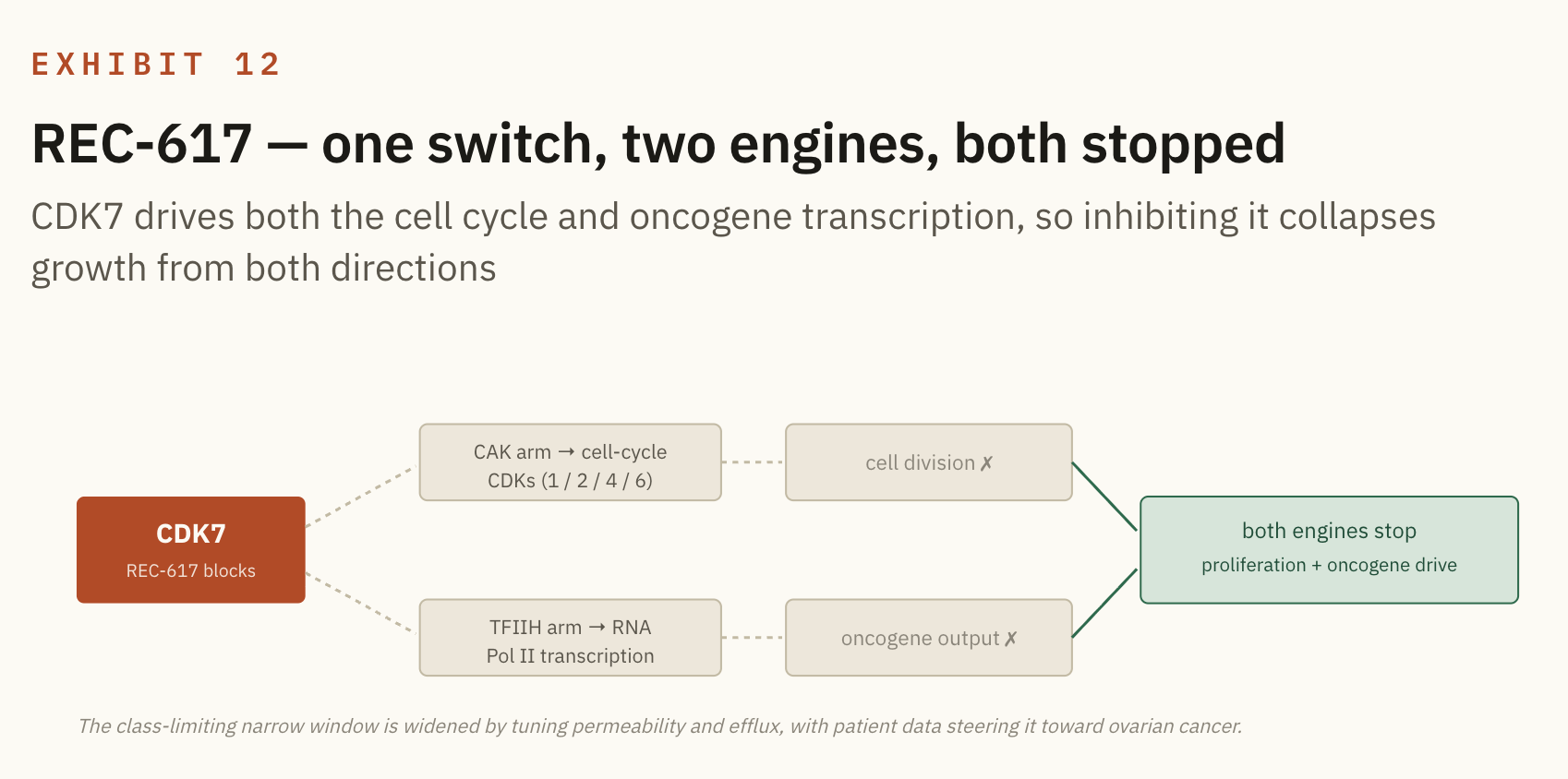
REC-617 (CDK7, solid tumours). CDK7 is the dual master switch: one arm licenses the cell cycle, while the other fires transcription of the super-enhancer genes that oncogenes depend on, so blocking it hits the tumour's growth engine from both sides at once.
The whole class has been capped by a narrow therapeutic window, and the platform edge is chemistry tuning permeability and efflux to widen that window, alongside using patient data to steer the drug toward ovarian cancer rather than the crowded breast setting.
REC-1245 (RBM39, solid tumours and lymphoma). This is the one covered at length in Section IV: a splicing factor with no pocket, reached by degradation rather than inhibition, and found via the CDK12 analogy. It is the expression layer in its purest form, because it does not change which genes exist but corrupts which version of the protein gets made, and the tumours addicted to high splicing throughput die first. It is the lead novel-target receipt, and its mechanism is the one already drawn in Exhibit 3.
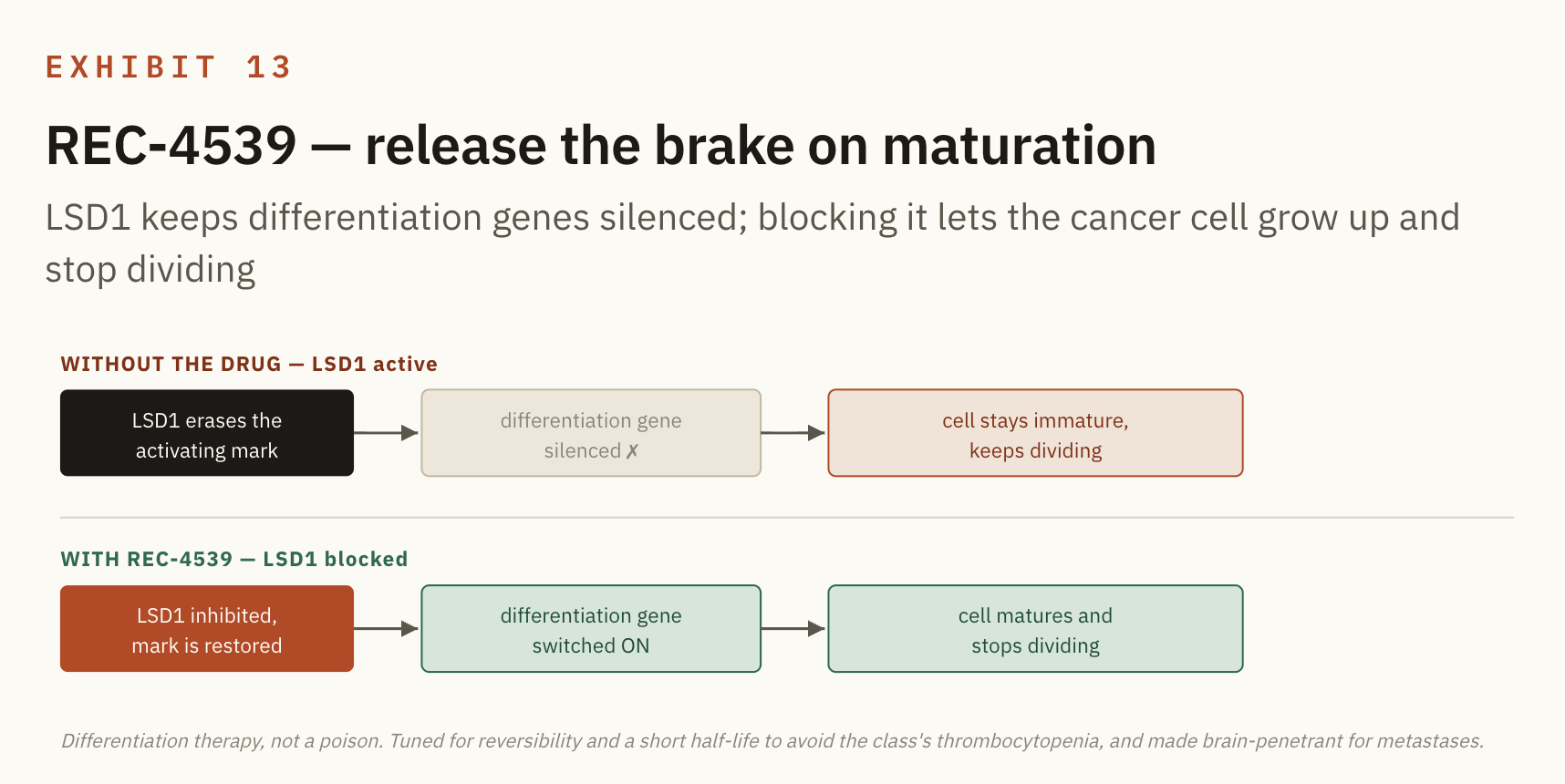
REC-4539 (LSD1, small cell lung cancer and AML). This is the epigenome tuning. LSD1 is a histone demethylase, an eraser that strips activating marks to keep cancer cells locked in an immature, proliferating state, so inhibiting it pushes the cell to differentiate instead.
The biology is known and was killed repeatedly by thrombocytopenia, and the platform edge is a brand new chemical scaffold designed for reversibility and a shorter half life to dial out that platelet toxicity, plus brain penetrance for the patients who develop brain metastases.
8.0 A new CEO
In the third quarter of 2025, the founder stepped back. Chris Gibson, who built Recursion from zero and arguably created the TechBio category, moved to Chairman, and Najat Khan, who had joined in 2024 to run R&D and Commercial, took over as CEO effective the first of January 2026.
This matters because the two profiles are genuinely different, and the company needs the second one now. Gibson is the visionary founder, unapologetic, the person who convinces the world a new category exists, whereas Khan is the operator. She came from running R&D strategy and data science at J&J, and at Recursion she led the Exscientia combination, the largest TechBio deal of 2024 and the thing that handed the company its chemistry engine in the first place. The vision is built; the job now is translation, discipline and proof, and that is precisely her skill set.
Khan has a base salary of $680,000. On top of that, equity: an initial grant of $500,000 in restricted stock and $500,000 in options, then a much larger grant with an aggregate value of at least $7.5 million, split evenly between restricted stock and options, all of it vesting over four years.
So roughly 97% of her pay is equity and her cash salary is only about 3% of the total, which makes the alignment real and long dated. The options only pay if the stock rises, tying her directly to shareholder upside.
A large slice is time vesting restricted stock, which pays on tenure as much as on performance, and her direct ownership is still modest because she is a hired operator rather than a founder with a decade of stock. The net read is that she is well aligned on the upside and locked in for four years, though without true founder skin in the game, which is the correct profile for an execution chapter.
Her stated philosophy is also exactly the one I would want: build a proprietary data moat that translates into better medicines. That is Ontology Velocity in plain language. She is not promising a blockbuster, she is promising to make the model of biology improve faster than anyone else's and to spend every dollar as if she were an investor, and that is the right idea.
Since she took over:
Molecules are moving faster into humans.
Financial discipline is up.

Molecules are moving faster into humans. RBM39 went from preclinical to dosed with clean early safety, LSD1 dosed its first patient, and every clinical stage programme now has a readout inside the next twelve to eighteen months. On cost, the discipline is visible: operating expense down by roughly a third year on year, full year guidance held under $390 million, and the runway pushed out to early 2028 even as the cash balance fell, because partner milestones are now funding the burn.
That last point is the whole operating thesis in one line. She is spending the engine’s own revenue to buy the time the clinical readouts need, so that if the readouts confirm, the re-rate follows, and if they do not, the discipline means she gets more shots before the money runs out.
9.0 Conclusion
The four pieces of evidence hold up. The pipeline contains genuine novelty, the discovery is an order of magnitude leaner than the industry and the leanness is stable, which tells you it is a process rather than a fluke. Some of the molecules do things old methods could not, both by reaching the undruggable and by tuning away the toxicity that buried whole classes. And pharma is has paid half a billion dollars in cash for the engine's raw output, which is the one validation that does not need a single drug to succeed.
Put together, that is the shape of a Singularity Scaler: a loop that learns biology faster than anyone, funds its own improvement, and bends its cost curve down while the value curve bends up. The operator now in the seat understands exactly this, and her incentives are locked to it for four years.
I don’t have a position and I will be watching Recursion closely going forward.
⚡ If you enjoyed the post, please feel free to share with friends, drop a like and leave me a comment.
You can also reach me at:
Twitter: @alc2022
LinkedIn: antoniolinaresc
exciting company and amazing that you did all this work in a few days.. i m stunned..
You have my respect!
Gran pieza. Solo una duda sobre el flywheel: el motor de descubrimiento escala a coste marginal casi 0, pero la fase 3 y la FDA siguen cobrando tarifa completa. El “Singularity Scaler” sobrevive al cuello de botella clínico, o ahí la curva de costes se niega a doblarse?